
Rust is best known for its memory safety features. At the same time, most web services today are already built using memory-safe languages such as Java, Python, Go or C#. Are there still compelling reasons to use Rust when the competing language is equally memory-safe?
Perhaps there is a performance difference? Let’s test the hypothesis that Rust may offer superior performance compared to C#. This article showcases how the two compare when examining some very simple data processing code of the sort you might have in a web API handler, implementing unremarkable algorithms to execute unremarkable transformations on data.
Note that the scenario below is a very small slice of the service workload landscape and the TechEmpower web framework benchmarks potentially offer a much better overview of broad-scope service performance. This article exists to showcase the difference that remains if we remove frameworks from the equation and just have some straightforward no-nonsense algorithmic code.
Scenario
An asynchronous function receives the 50 000 first digits of Pi and outputs a censored version, where digits are replaced with ‘*’ if they are smaller than the previous digit, ignoring the starting “3”. The output is written to a byte stream as UTF-8 bytes.
Example input: 3.1415926535897932384626433
Example output: 3.14*59*6**589*9**38*6*6**3
This scenario allows us to examine multiple generalizable factors while being very ordinary code:
- Working with basic alphanumeric strings.
- Working with basic asynchronous functions.
- Transforming a data set based on simple rules.
- Managing temporary buffers to process data in a performant manner.
- Writing processed data to a generic output as UTF-8 bytes.
The async runtime is out of scope
Most web service code is asynchronous, so we will use asynchronous function signatures in example code to ensure function call overheads are realistic. However, all logic will execute synchronously.
This is a legal pattern (asynchronous code is allowed to complete synchronously) and allows us to ensure that differences in async task scheduler implementations used by the different execution platforms do not influence the measurements.
Optimized algorithm with in-place byte manipulation
A high-performance algorithm processes the input as UTF-8 bytes. We only intend to process the digits of Pi and can skip string encoding operations as UTF-8 is a superset of ASCII. See my previous article on algorithm optimization to understand why this algorithm is optimal.
In ASP.NET Core request handlers, it is performance-critical to constrain response writes to no more than 4096 bytes per write operation so we pick this as the maximum size of a single write for both the C# and Rust implementation.
This fact about 4096 byte writes is the case in .NET 8 (likely due to 4096 byte limit of PinnedBlockMemoryPool) but is ultimately an undocumented implementation detail that may change in newer versions of .NET.
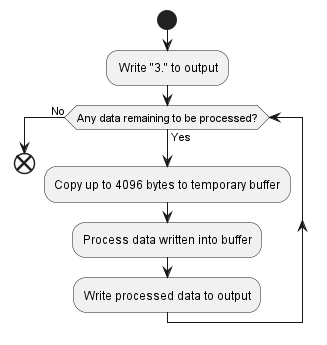
The optimal algorithm reduces down to taking 4096 byte chunks of the input, censoring them in-place in a temporary buffer, and writing them into the output mechanism.
| Optimized algorithm | C# | Rust |
| CPU time | 124.4 μs | 29.2 μs |
| Memory allocated | 0 bytes | 0 bytes |
This shows that even a reasonably well optimized C# implementation of this simple algorithm is significantly slower than an equivalent Rust implementation.
Understanding the reasons for this performance difference is beyond the scope of this article, though please leave a comment if you have valuable insights about it. Here is the generated assembly code, should you wish to inspect it:
C# code: InPlaceWriteCensoredDigitsOfPiAsUtf8BytesAsync() on GitHub.
Rust code: write_censored_digits_of_pi_inplace() on GitHub.
Typical algorithm with LINQ and iterators
Hand-crafted optimized implementations such as the above are not typical code, except in rare situations where code is deliberately optimized for performance. A naive implementation uses LINQ (C#) or iterator transformations (Rust) to transform data from one form to another using more canonical patterns.
Optimization is the exception, so we must also consider and compare the typical unoptimized implementation.
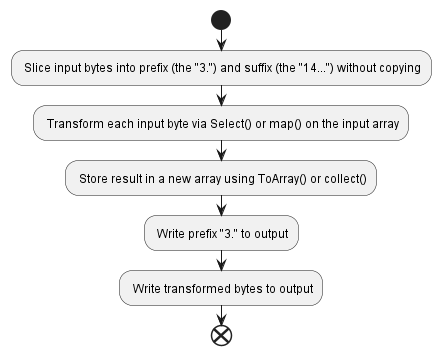
LINQ is infamous for being an easy path to inefficient code in the C# universe. Can Rust do better and maintain high performance when using iterator transformations?
We drop the 4096-byte write requirement in this implementation, as it is only relevant for optimization and is not anything we would find in naive code.
| Typical implementation | C# | Rust |
| CPU time | 208.3 μs | 84.9 μs |
| Memory allocated | 50 216 bytes | 50 148 bytes |
Both Rust and C# exhibit decreased performance here compared to the optimized algorithm. While Rust still comes out ahead, the relative margin is smaller – switching from in-place modification to iterator transformations greatly slowed down the Rust implementation.
Both implementations allocate equivalent amounts of memory during execution. Most of this memory is used to temporarily store the output of the transformation. This is expected and we observe no impactful difference in memory allocation behavior.
C# code: IterativeWriteCensoredDigitsOfPiAsUtf8BytesAsync() on GitHub.
Rust code: write_censored_digits_of_pi_iterative() on GitHub.
C# strings are an extra price to pay
Rust strings are sequences of UTF-8 bytes. This helps avoid some overheads, as most of the web is UTF-8. However, C# uses UTF-16 strings, which require extra encoding to convert to UTF-8. This adds additional cost to many operations.
For the sake of implementation equality, the above “optimized” and “typical” implementations processed the input as UTF-8 bytes. However, in truth, this is anomalous for C#! It is far more typical to receive textual input as strings. For a realistic comparison, we must consider this factor.
What do we see if we convert the typical C# implementation from processing UTF-8 bytes to processing strings?
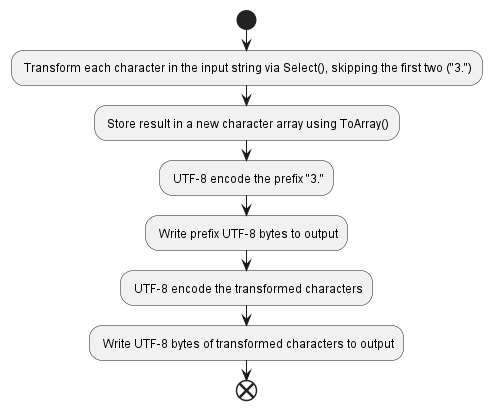
| Typical implementation | C# byte[] | C# string | Rust |
| CPU time | 208.3 μs | 350.8 μs | 84.9 μs |
| Memory allocated | 50 216 bytes | 282 059 bytes | 50 148 bytes |
Receiving the input as a string greatly increases the CPU time required by the algorithm and showcases the true cost of typical a C# implementation. Significant memory allocations must be performed to perform the string decoding/encoding.
C# code: IterativeStringWriteCensoredDigitsOfPiAsUtf8BytesAsync() on GitHub.
Remember that this code was deliberately written in a naive style, without focusing on optimization. This is typical for most production code. It is certainly possible to write even string-based code more efficiently!
Conclusions
For both examined realistic scenarios (optimized and typical string-based), the Rust CPU time advantage is -75%. In other words, the exact same algorithm is 4x faster when implemented in Rust!
With the optimal algorithm, both implementations are allocation-free but for the naive string-based implementation, Rust also has a memory advantage of -82%.
While such findings do not generalize for arbitrary code, the size of the difference is quite drastic and was personally rather unexpected. This suggests that Rust can have significant performance and/or cost advantages even over industry-leading memory-safe languages like C#.
Do we sacrifice anything?
A 4x performance increase is enticing but what do we pay in exchange? An immediate thought is that perhaps the Rust code is more difficult to write or more verbose/complicated to understand.
This is not the case – the code for both C# and Rust looks essentially equivalent. The Rust code is not in any sense harder to maintain, test or write. Writing the code took equivalent time for both C# and Rust implementations (and I am far more experienced in C#, so my writing skills are biased to disfavor Rust).
The main disadvantage of Rust is the general immaturity of the ecosystem and tooling. Code-wise, it is perfectly readable and writable without extra hassle, at least in the scenario explored by this article.
How to reproduce?
The code is available on GitHub: https://github.com/sandersaares/picensorship-rs
To run the C# benchmarks, open censoredpi-cs in Visual Studio, build with the Release configuration and run the app. The results will include both CPU and memory measurements.
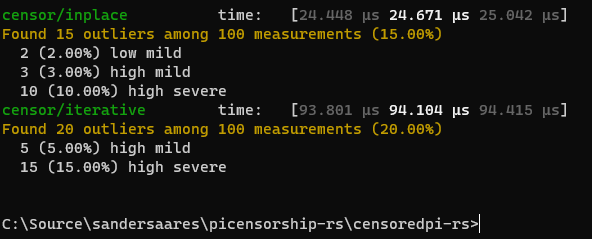
To run the Rust CPU benchmarks, run “cargo bench” in the censoredpi-rs directory. The results will include only CPU time measurements.
To measure Rust memory allocations:
- Open a Linux terminal in the censoredpi-rs directory.
- Install Valgrind (e.g.
sudo apt install valgrind). - Run cargo build –release
- Run valgrind –tool=massif target/release/iterative or valgrind –tool=massif target/release/inplace
- Run ms_print massif.out.12345 where the number in the filename is the process ID of the app that was executed.
- Interpret the output (outside the scope of this article).

Are you sure that these results mean anything at all?
I’m not a C# programmer at all and I’m barely a programmer really but when I looked at the C# code I could see that it was doing a lot of overhead just in the way the code was written.
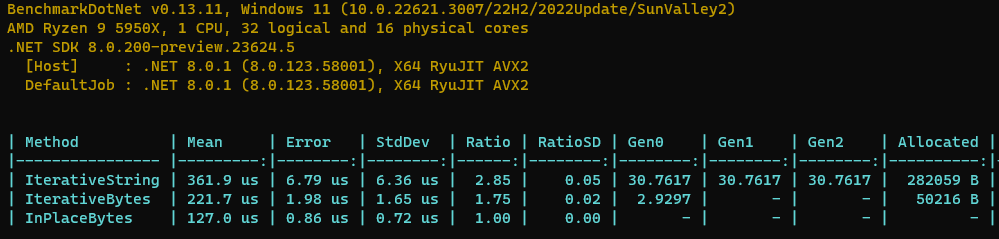
When I ran the test on my machine, the IterativeString had a mean of 709 microseconds.
I replaced the code that censors the digits of pi using a simple char array and a for loop and the mean became 336 microseconds.
My 2 minute hack halved the run time. Am I missing something? Are there some real C# coders out there that can shine some light on this
LikeLike